
Is Human Memory like RAG?
Surprisingly, yes! We can use the differences to forecast what's going to happen with memory in agentic LLMs.

Human memory is the result of many hundreds of millions of years of evolutionary work. Early animals, about 500 million years ago, had something like reinforcement learning, tracking the success of actions in context. Then, some time later, early vertebrates added the hippocampus for something like episodic memory. And in the last part of our story, the neocortex developed in mammals to consolidate and integrate these memories to improve generalization.
These days, we’re building memory into LLM agents that need to remember things between tasks, and learn from their experience. We’re basically speedrunning in years the systems that took evolution much longer. Memory in humans has clear parallels to memory in agents. This is on my mind because I've been reading the excellent book The Evolution of Memory Systems, while at the same time I’m working on adding memory to code generation systems. LLMs are catching up to human memory, but they’re not there yet!
I recently read a blog post titled "Why I No Longer Recommend RAG for Autonomous Coding Agents", not because RAG is bad, but because without proper scaffolding, it actively harms performance. This is exactly the problem evolution spent millions of years solving.
Reinforcement Learning in the Brain
Travel back far enough in evolutionary time—past mammals, past vertebrates—and you'll still find reinforcement learning. Mollusks and crustaceans exhibit Pavlovian conditioning despite their simple nervous systems. A sea slug learns to retract its gill after repeated shocks. A crab learns which crevices hide food. RL solves a fundamental computational problem for animals: in a world where you can't store everything, remember what worked. Instead of episodic details, just update your policy based on outcomes. Evolution discovered this principle so early that it's conserved across virtually all animal life; dopamine serves a similar purpose in insects as it does in humans.
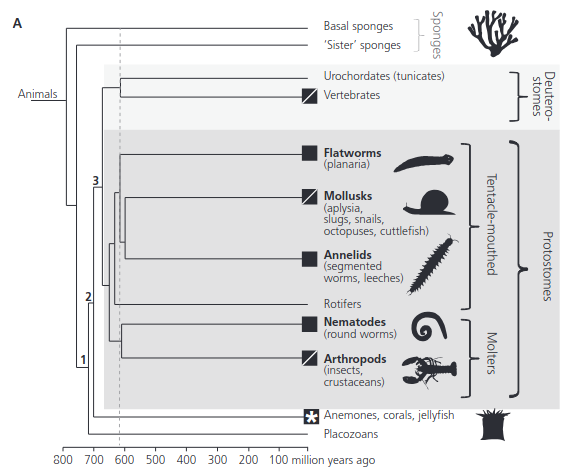
Reinforcement learning obviously isn't a new thing in ML. In addition to game AI, RLHF is now standard for training LLMs. But there’s a big difference in biological RL: animals continuously update their value functions based on outcomes. A raccoon will learn which human foods are tasty, and which give it a stomach ache. LLMs are not typically set up to learn from deployment experiences. This distinction between 'RL for training' and 'RL as memory' becomes important when we consider autonomous agents, and we’ll come back to this at the end.
RAG on the Brain: the Hippocampus
If you were designing a memory system from scratch, you might build something like the hippocampus. It stores episodic memories as sparse, high-dimensional vectors. When you need to recall something, it performs similarity matching between your current neural state and stored patterns. The retrieved memories then get integrated with ongoing cortical processing. This is basically RAG!
We know this, in part, because of a patient known as H.M.. In 1953, surgeons removed most of his hippocampus to treat severe epilepsy. The surgery worked — his seizures stopped. But something else stopped too: his ability to form new episodic memories. HM could still learn motor skills (that's a different system), but he couldn't remember meeting you five minutes after you left the room. Every day was groundhog day. He essentially lost his biological RAG system, meaning he could still process information, still think clearly, but couldn't store or retrieve new experiences. (It was actually a bit more complicated than this, and we'll get to that in a minute.)

The neural implementation is elegant. A small circuit of neurons called CA3 has dense recurrent connections, where every neuron talks to every other neuron. This creates an attractor network, which has been liked to a biological Hopfield network. This is a good summary of the theory that vector similarity memory is implemented like that.
Give it a partial pattern (the smell of coffee), and it completes to the full memory (the entire café conversation). It's an associative memory that “fills out” a partial memory, just like modern vector databases use similarity metrics to find the best match.
Humans appear to access hippocampal memory frequently and sequentially, building up memories sequentially. This reminds me of how agentic LLM systems can use tool use to access memories.
Inference Time Training
There's something weird about amnesia. Despite failing to learn new memories, H.M. could still remember his childhood perfectly. So could other patients with hippocampal damage. This puzzled neuroscientists for years. If the hippocampus stores memories, shouldn't losing it erase everything?
Neuroscientists now mostly believe in a theory called memory consolidation, which approximately says that we use an episode capture system with a replay buffer to train a more general system. The hippocampus has a high learning rate, so it captures memories as they happen, and then replays them during quiet moments for the neocortex. The neocortex has a slow learning rate, and it is exposed to the memories many times, so it is able to generalize over them.
Right now, the ML community is experimenting with LLMs that perform inference time training, and it sometimes works. For example, if an agent executes tool use to read the contents of a file, then training could occur on the model at that time to train it to predict the contents of the file. Among other problems, it’s computationally expensive to do this much finetuning, but this is likely to be solved.
Reinforcement Learning Part 2
A current challenge for users of AI agents is that they don’t naturally learn from their mistakes. The current best solution is to use developer-defined coding rules that track best practices for coding to follow. Alternatively, to track the mistakes the agent has made in the past so that they will see the note and hopefully do it differently in the future. The pitfall to this is that these rules can become very large, even for models with very large context lengths.
In contrast, humans and other animals are doing RL finetuning in real time. They do inference time training to track what works and what doesn’t. We need agentic LLMs to use their ongoing experiences to guide their future actions in the same way that reasoning systems like r1 or o3 learned from reasoning traces during training. This is extremely analogous to how RL gameplay systems typically use a replay buffer to train on memories of recently played games.
I expect that we’ll get there in a few years!
Where do We Go from Here?
Agentic AIs like Claude Code and OpenAI’s o3 are already able to search the web, and the MCP protocol provides good ways to integrate vector database search with agentic LLM execution. I expect these methods will continue to expand and get better rapidly over the next one to two years. But I expect we’ll start to see the pitfalls with this method. LLMs will be repeatedly searching for the same content. Or worse, they’ll sometimes fail to search for the needed content, and they’ll behave badly, without the necessary context. As the scope of problems gets bigger and bigger, the amount of learning that needs to occur “on the job” will grow, and grow.
These longer tasks will require more memory, and continuous doublings will overwhelm the agents ability to consistently get the right information through RAG, through search, or through other context management schemes. When that happens, there will be growing impetus for inference-time-training. Once we figure out the technical details of doing that training efficiently, online RL will quickly follow.